

過渡期のUXリサーチ
2026年、UXリサーチ領域でSynthetic User(合成ユーザー)が急速に注目を集めています。LLMを活用した仮想ユーザーが、数分でインタビューに答え、UIをテストし、フィードバックを返します。リクルーティング不要、24時間稼働、コストはほぼゼロという特徴があります。
Lyssnaの2026年UXリサーチトレンド調査[1]では、UXリサーチャーの88%がAI支援分析をトップトレンドと認識し、48%がSynthetic Userに注目していることがわかりました。興味深いのは、研究者たちの予測が「大きな懸念を伴う熱狂(significant skepticism alongside the enthusiasm)」と表現されている点です。
これは典型的な技術の過渡期の反応です。新しい可能性への期待と、既存の方法論への信頼。両者が拮抗する時期だからこそ、冷静に問うべきことがあります。
組織はどう進化すべきか。リサーチチームの役割はどう変わるのか。そして、ユーザー中心設計の文化をどう深化させるのか。
2026年の現実:可能なことと限界
実現できること
速度とスケールの優位性
従来は週単位だった調査が分単位で完了します。10人の参加者を集める代わりに、100の合成ユーザーバリエーションを瞬時に生成できます。
リクルーティング、スケジュール調整、インセンティブ支払いといった調整コストがゼロになることで、アジャイル開発の短いスプリント内でも複数回のユーザーフィードバックサイクルを回せるようになります。これは特にリソースが限られたスタートアップにとって大きな利点です。
UIテストの部分的自動化
UxiaやSynthetic Users社のプラットフォームは、Figmaプロトタイプに対してユーザビリティ問題を指摘できます。複数の検証研究[2]では、ナビゲーションの摩擦点やCTAの不明瞭さについて、人間とほぼ同等の指摘を行えることが確認されています。
特に「明らかな」ユーザビリティ問題(ボタンが見つからない、フローが複雑すぎる、など)については高い精度で検出できるため、開発初期段階での問題の洗い出しに有効です。これにより、実ユーザーテストではより深い課題に時間を使えるようになります。
仮説生成と初期探索の高速化
新市場や新機能のアイデア段階で、「もしこんなユーザーがいたら?」という問いを高速で探索できます。プロトペルソナ生成、シナリオ検証、メッセージングテストが短時間で実施可能です。
例えばBooking.com[3]では、既存調査データに合成ユーザーパネルを追加することで、特定のサブグループ(ソロ旅行者など)の傾向を深掘りし、実データでは見落としていた設問の解釈ミスを発見できました。合成データと実データを比較する「検証の鏡」として活用することで、調査設計の質を高められます。
現時点での限界(ただし進化中)
統計的信頼性の問題
2025年の複数研究が明確に示しています。合成データは相関を歪めます。Development Corporate[7]の分析によれば、人間データと比較すると約50%の変数間関係が異なり、分散が人為的に狭いことがわかっています。
これが意味するのは、現時点では価格戦略、市場予測、セグメンテーション分析には使えないということです。5,000件の合成回答は、500件のリアルデータより正確ではありません。より精密に間違っているだけです。
ただし、LLMの訓練データの多様化やファインチューニング技術の進化により、この問題は徐々に改善される可能性があります。2027年、2028年の研究結果を注視する価値があります。
文化的文脈の欠落
西洋圏、英語圏、富裕層のデータで訓練されたモデルは、それ以外の地域で系統的に失敗します。World Values Surveyとの比較研究[7]では、プライバシー意識、支払い意欲、リスク認識において、非欧米圏で顕著な誤差が出ています。
これは訓練データの構造的問題であり、多言語・多文化データセットの拡充が進めば改善が期待できます。グローバル展開を目指す組織は、この限界を認識しつつ、現地での実ユーザー調査と組み合わせる必要があります。
感情の深さと矛盾の再現困難性
人間は矛盾し、迷い、文脈で変わります。AIは一貫性を保ちすぎます。Carnegie Mellon大学の研究者たち[7]は「AIは的確に話すが、人間の曖昧さを理解していない」と指摘しています。
実際のユーザーは「フォーラムは煩わしいから避ける」と言います。Synthetic Userは「積極的に参加するでしょう」と理想的回答をします。このギャップが、デザイン判断を誤らせる可能性があります[2]。
ただし、この「ギャップ」そのものが貴重な学びになります。AIと現実のズレを分析することで、私たち自身の思い込みや、設問設計の盲点を発見できるのです。
組織の進化:Conway’s Lawの視点
ツールは組織を形づくります。「組織がデザインするシステムは、その組織のコミュニケーション構造を模倣したものになる」というConway’s Law(コンウェイの法則)が示すように、どんなツールを採用するかは、組織の構造そのものに影響を与えます。
Synthetic Userの導入も例外ではありません。これは単なる「便利ツール追加」では終わりません。リサーチャーと実ユーザーの関係性、意思決定プロセス、組織内の情報の流れ方—これらすべてが変わる可能性があります。
リスク:空洞化のシナリオ
最も避けるべきパターンは、「AIで手軽に調査できるなら、リサーチ部署は不要」という短絡的なコストカットです。
起こりうること:
- リサーチャーの削減または役割縮小
- 実ユーザーとの接点が組織から消失
- AIが返す「都合の良い回答」への依存
- 思い込みの検証機会の喪失
- 競合の実ユーザー中心企業に敗れる結果
UXリサーチの専門家Konstantinos Papangelisは、ACM Interactionsのブログ記事[6]でこれを「静かなる危機(quiet crisis)」と呼んでいます。統計的作り物を人間の声と誤認させるマーケティングは、組織を盲目にする可能性があります。
機会:進化のシナリオ
より建設的なパターンは、Synthetic Userを「高速プロトタイピングツール」と位置づけ、リサーチャーが戦略的役割へシフトすることです。
実現できること:
- リサーチャーは「質問設計者」から「インサイト統合者」へ進化
- 合成データと実データの照合が新しいコアスキルに
- 調査の速度向上により、反復回数が劇的に増加
- より深い問い(なぜユーザーは矛盾するのか?)に時間を投資
- 組織全体のリサーチリテラシーが向上
EPAMが提唱する「Synthetic User Rehearsal」モデル[4]がこれに近い考え方です。リリース前に合成ユーザーで予行演習し、問題箇所を実ユーザーテストで精査します。AIの予測と現実のズレそのものが、学びになるという発想です。
鍵:リサーチャーを「進化の担い手」に
重要なのは、リサーチャーを「守護者」ではなく「進化の担い手」と位置づけることです。
従来のリサーチャーは「現場の声を守る人」でした。これからのリサーチャーは「AIと人間のインサイトを統合し、組織の学習速度を加速させる人」になります。
Synthetic Userは過去データのリミックスです。新しい発見はしません。しかし、それを出発点として、実ユーザーとの対話で予期しない行動や矛盾を捕捉する—このサイクルを高速で回せる組織が、2027年には優位に立つはずです。
実験するための実践ガイド
2026年は「正解を待つ」のではなく「小さく試して学ぶ」時期です。
推奨される実験領域
1. 初期探索・仮説生成
- 新市場や新機能のコンセプト段階
- 「こういうユーザーがいたら」の思考実験
- インタビューガイドの下書き作成
- リスクの低いアイデアブレスト
2. UI/UXテストの前段階
- プロトタイプの明らかなユーザビリティ問題
- ナビゲーション摩擦点の洗い出し
- 複数デザイン案の方向性比較
- 開発前のクイックバリデーション
3. リアルリサーチの補完
- 既存インタビューデータから追加ペルソナ生成
- サーベイ設問文の事前テスト
- エッジケースシナリオの探索
現時点で避けるべき領域
1. 戦略的意思決定
- 価格戦略
- 市場規模予測
- プロダクト方向性の最終判断
- グローバル展開戦略
2. 統計的検証が必要な分析
- A/Bテストの母集団推定
- セグメンテーション分析
- 行動予測モデル構築
3. 深い共感と発見が必要な調査
- 新しいペインポイントの発見
- 感情的動機の理解
- 文化的文脈の把握
- ユーザーの矛盾や葛藤の探索
実験ワークフローの例
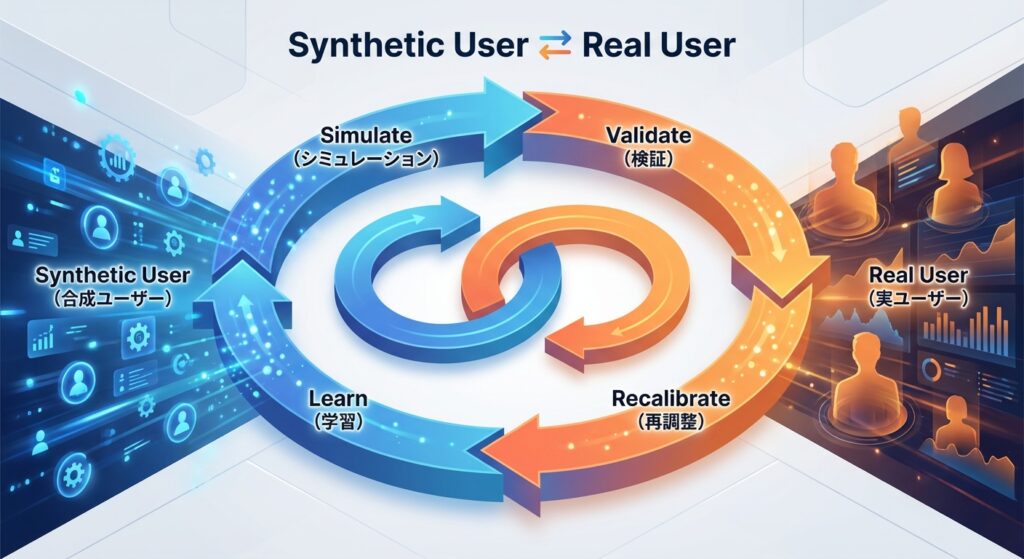
EPAM型:Simulate → Validate → Recalibrate → Learn[4]
- Simulate(合成): Synthetic Userで100パターンのシナリオを高速検証
- Validate(検証): 上位3パターンを実ユーザー10名でテスト
- Recalibrate(再調整): AIと現実のズレを分析—なぜズレたのか?
- Learn(学習): 組織の仮説形成能力を強化し、次のサイクルへ
このサイクルを開発全体に組み込むことで、CI/CDのように学習が自動化されます。
Booking.com型:Mirror(鏡)としての活用[3]
- 既存サーベイに合成ユーザーパネルを追加
- 実データと合成データを比較
- ズレこそが宝:差異が出た箇所を精査→設問設計の盲点を発見
- 調査設計の質が向上し、次回の実ユーザー調査がより的確に
意思決定者への提言
1. 「実験予算」としての投資
Synthetic Userを「コスト削減ツール」と見れば、リサーチ部門は縮小されます。「実験加速ツール」と見れば、学習速度が上がり、競争優位が生まれます。
問うべき問い:
- このツールで削減した時間を、どんな実験に再投資するか?
- 失敗から学ぶサイクルは以前より速く回っているか?
- 実ユーザーとの接点は増えているか、減っているか?
2. 「Safe-to-Fail」実験の設計
合成データの利用範囲を、失敗しても影響が小さい領域から始めます。
セーフティネット設計:
- 低リスク領域(探索、仮説生成)から開始
- 必ず実ユーザー検証のゲートを設ける
- 「AI生成」を明示し、過信を防ぐ
- 四半期ごとに振り返り:何を学んだか?
- リサーチャーが「ストップ」と言える文化
3. スキル進化への積極投資
リサーチャーには新しい能力が求められます。これは脅威ではなく、キャリアの可能性拡大です。
2027年のリサーチャーに必要なスキル:
- プロンプトエンジニアリング(AIから最良の回答を引き出す技術)
- 合成データと実データの照合分析(ズレを読み解く目)
- AIバイアスの検出と補正(批判的思考)
- ハイブリッド調査の設計(新しい方法論の創造)
- ステークホルダーへの「可能性と限界」の説明(翻訳者として)
これらのスキルを持つリサーチャーは、組織内で「AI時代のユーザー理解の専門家」として、より戦略的な役割を担えます。
結論:2027年を見据えて
Synthetic Userは2026年時点で、過渡期の技術です。探索には強力、検証には不十分、戦略判断にはまだリスクが高い—というのが冷静な評価です[5]。
しかし、LLMの進化速度を考えれば、2027年、2028年の状況は大きく変わっている可能性があります。
今、問うべきは「使うか、使わないか」ではありません。 問うべきは「どう学習曲線を登り始めるか」です。
Conway’s Lawが教えるのは、ツールが組織を形づくるということです。Synthetic Userを「脅威」と見る組織は、防衛的になり、学習が遅れます。「実験の機会」と見る組織は、失敗から学び、進化します。
2027年、ユーザー理解において優位に立つのは、以下のような組織です:
- 実験する組織:小さく試し、失敗から学ぶサイクルを回している
- ハイブリッドな組織:AIと人間のインサイトを統合する方法論を確立している
- 進化するリサーチ組織:リサーチャーが新しいスキルを獲得し、戦略的役割を担っている
- 文脈を大切にする組織:AIの効率性を活かしつつ、実ユーザーとの対話を深めている
技術は不完全です。しかし、不完全な技術から学ぶ能力こそが、組織の競争力になります。
答えはツールの中にはありません。 答えは、あなたの組織がどう学び、どう進化するかにあります。
執筆ノート
本記事はClaude Sonnet 4.5(Anthropic, 2026年1月時点)との協働で執筆しました。リサーチ資料の分析、構造化、執筆はAIが支援し、内容の監修・方向性の決定・最終判断は筆者が行っています。
Synthetic Userという技術を論じる記事が、AIとの協働で作られていること自体が、この記事で提唱する「ハイブリッドアプローチ」の実例です。AIの効率性と人間の判断を組み合わせることで、より速く、より深い考察が可能になると考えています。
ただし、AIアシスタンスには限界があります。引用の検証、論旨の妥当性、読者への適切性については、最終的に筆者が責任を負います。
参考文献
[1] Lyssna (2026), “UX Research Trends 2026”,
https://www.lyssna.com/blog/ux-research-trends/
[2] James Newhook, Interaction Design Foundation (2025),
“Are AI-Generated Synthetic Users Replacing Personas? What UX Designers Need to Know”,
https://www.interaction-design.org/literature/article/ai-vs-researched-personas
[3] Qualtrics (2025), “Using AI to Scale Up Research”,
https://www.qualtrics.com/articles/strategy-research/using-ai-to-scale-up-research/
[4] EPAM (2025), “Synthetic Users: Rehearsing the Future”,
https://solutionshub.epam.com/blog/post/synthetic-users
[5] Uxia (2025), “Synthetic Users vs. Human Users”,
https://www.uxia.app/blog/synthetic-users-vs-human-users
[6] Konstantinos Papangelis, ACM Interactions (2025),
“The Synthetic Persona Fallacy: How AI-Generated Research Undermines UX Research”,
https://interactions.acm.org/blog/view/the-synthetic-persona-fallacy-how-ai-generated-research-undermines-ux-research
[7] Development Corporate (2025),
“Synthetic Responses in Market Research 2025”,
https://developmentcorporate.com/saas/synthetic-responses-market-research-2025/
